GoogleAIの勉強:4時間目「損失を減らす」①
今回のGoogleAI講座は少し長いので、何回かに分けて見ていきたいと思います。テーマは「損失を減らす」期待値と実際の値の差が損失でしたがコレを少なくするのが今回の講座の目的のようです。
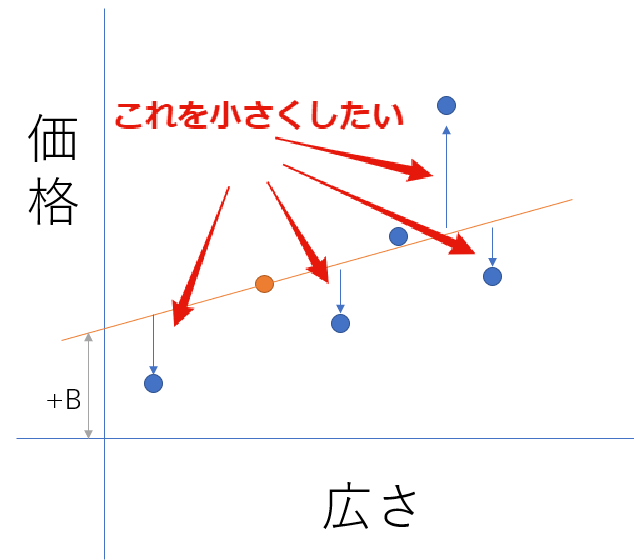
そのために必要なのが「モデルの訓練」であり、その良い方法は「反復アプローチ」なんです。
講座の概略
損失と傾きの関係をまずは押さえておきます。 まずはわかりやすくするために下の図を見てみましょう
なんかいろいろ書いてありますが、一つずつ見ていきましょう。 今回用に適当に作ったグラフですがまずは、XとYの関連を見てみます
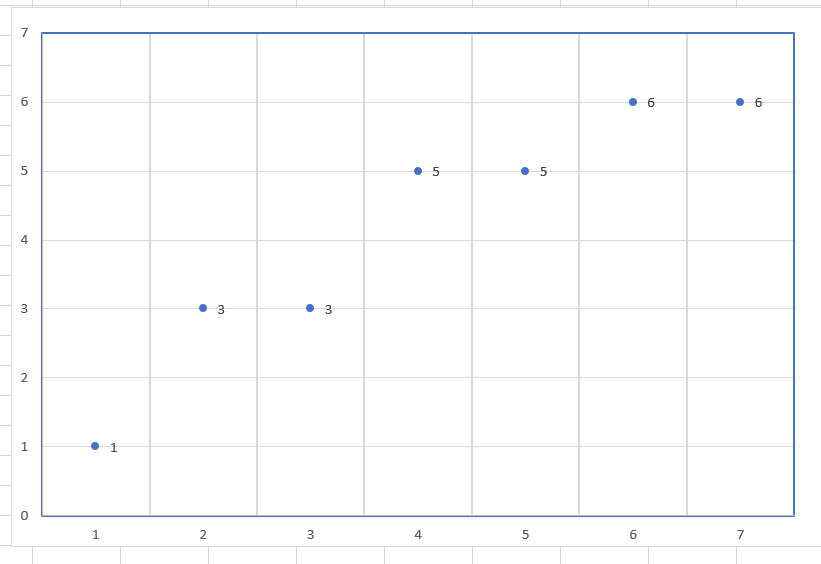
なんとなくYが増えればXも増えるのはわかりますよね。ではXが「3.5」の場合にYはいくつになるのでしょう。これを予測したいとします。
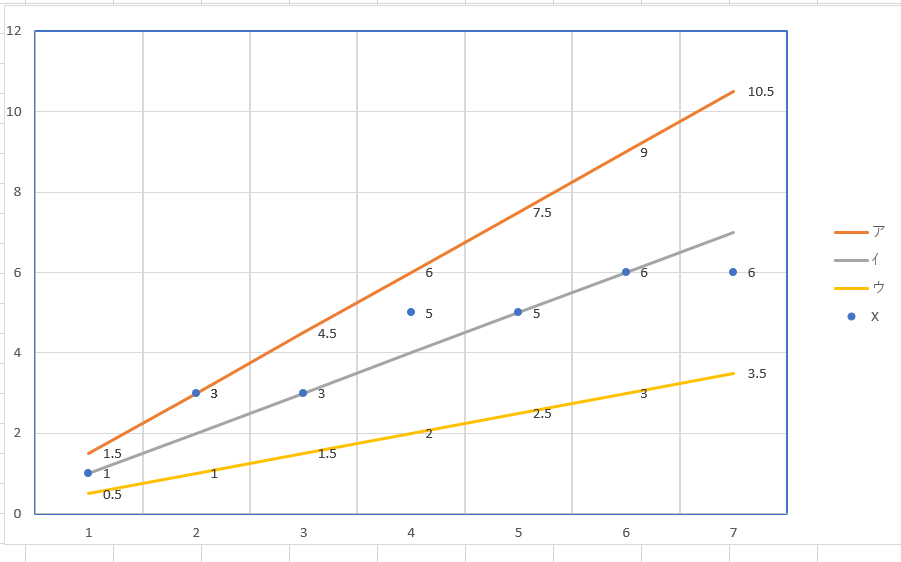
ではここに傾きの違う3本の線を入れてみます。
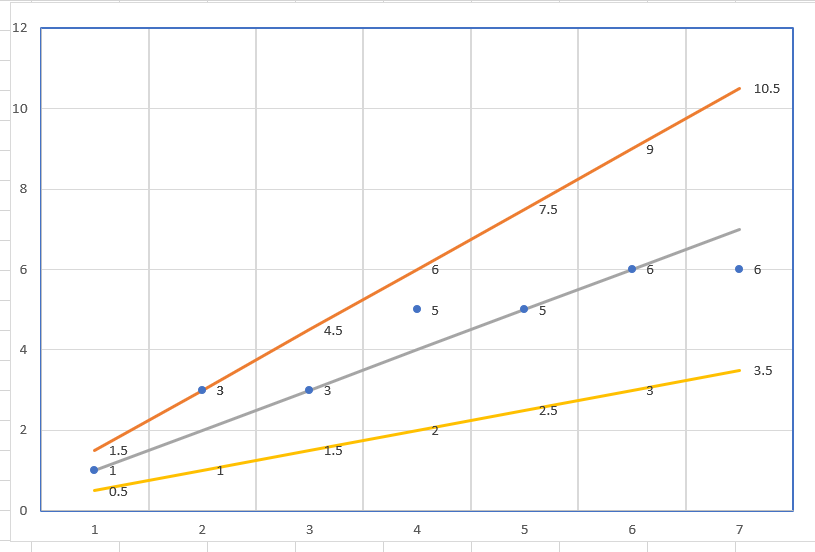
オレンジ・灰色・黄色のラインです。この中で実際の値と近いラインは灰色の線なのは一目瞭然ですよね。ついでに、Xが3.5ならYも3.5かな?という予想もつきます。 それで、この傾きを機械学習によって導かないとならないわけです。 傾きと損失の関係をグラフにするとお椀型になります。
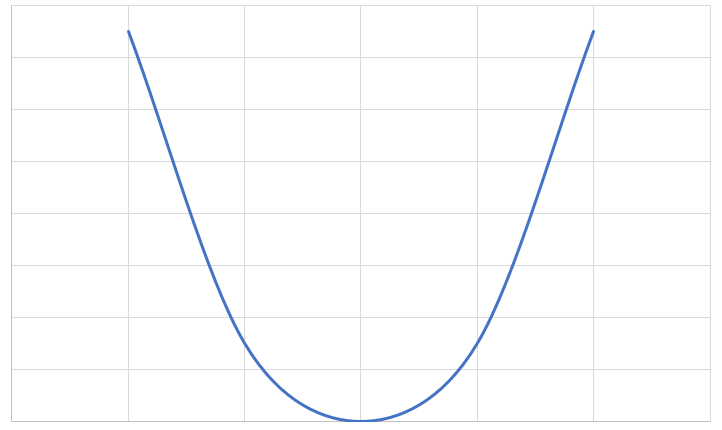
Xと軸が傾きの値で、Y軸が損失の量です。傾きが0からプラスへ変化すると損失が少なくなって、ある一点を超えると再び大きくなります。 この損失が一番小さくなる値を探すのが今回のテーマなわけです。
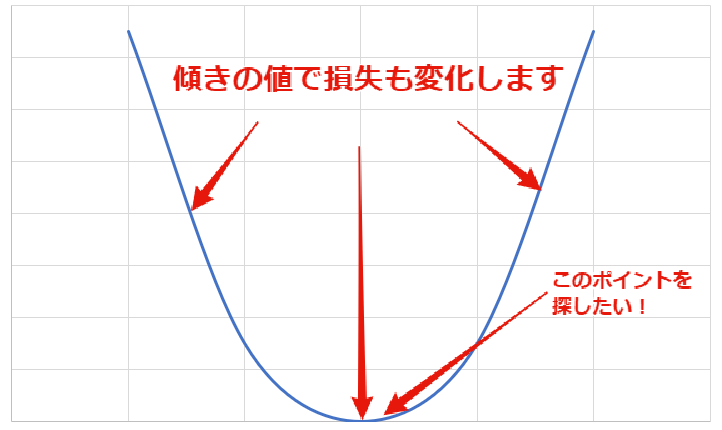
基本的には、小さい値から順に検証していって、ベストの値を探します。 たくさん学習していれば、ぐんぐん進んで検証できます。
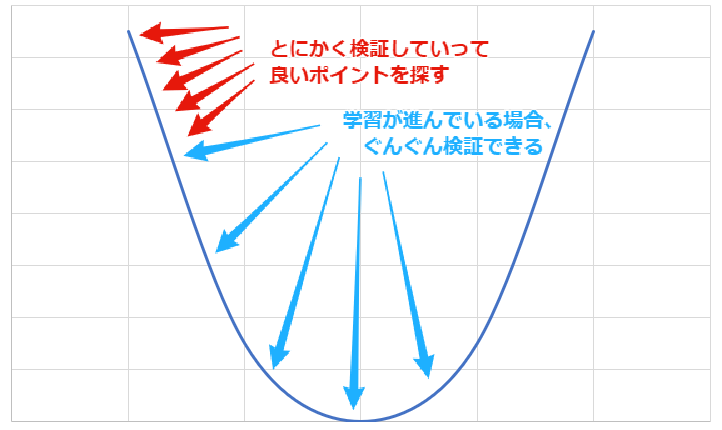
そして、もしベストの値を行き過ぎて検証が進んだ場合は、戻ってくるとか。 ちなみにこれは、Xが増えればYも増えるという条件下のみ使える方法で、その他の型の場合はまた別の方法が必要みたいですが、これはまた改めて説明します。 このような内容が今回のビデオになっています。詳しい内容を下に載せておきます。
こんにちは、私の名前はCassandra Xiaです。私はGoogleのプログラマーです Google内の他のグループがテンソルフローを使用するのに役立ちます。 このセクションでは、損失を減らす方法について説明します。 以前は、損失をどのように計算するかを学びましたが、 それを最小化するモデルパラメータ? まあ、パラメータ空間内に入る方向があったらうれしいです。 私たちが取った新しいハイパーパラメータの各セット それ以前に比べて損失が少なかった。 方向を得る1つの方法は、グラジエントを計算することです。 モデルパラメータに関する損失関数の導関数。 平方損失のような単純な損失関数の場合、微分は簡単に計算できます。 モデルパラメータを効率的に更新することができます。 iterated approachと考えてください。 データが入ったら、そのデータの損失関数の勾配を計算します。 負の勾配は、モデルパラメータをどの方向に更新するかを示します 損失を減らすために 私たちはその方向性に一歩踏み出し、 モデルの新しいバージョンを取得して、今度はグラデーションと繰り返しを再計算することができます。 一次元でふりをする、これは私たちの損失関数です。 これは、単一モデルパラメータthetaを損失にマッピングします。 シータのランダムな値または初期化を開始すると我々はそれに対応する損失を達成する。 次に、負の勾配を計算して、損失を最小限に抑えるためにはどの方向に行かなければなりません。 その方向で勾配のステップをとると、新しい損失が生じます。 我々は、その方向への勾配のステップを、私たちは地元の最小を通過しました。 負の勾配は、私たちが出てきた方向に戻るように指示します。 負の勾配の方向にどれくらいのステップを取るべきですか? まあ、それは学習率によって決まります。 あなたがひっくり返すことができるハイパーパラメータ。 学習率が本当に小さければ、小さな勾配のステップをたくさん取ります。 最小値に達するために多くの計算を必要とする。 しかし、学習率が非常に大きい場合は、大きなステップを踏みます 負の勾配の方向に ローカル最小値を潜在的にオーバーシュートする また、損失が以前よりも大きくなる点に到達することさえあります。 より多くの次元では、これはあなたのモデルを発散させるでしょう。 その場合は、学習率を1桁程度低下させる。 勾配降下と呼ばれるアルゴリズムについて説明しました。 私たちはどこかに出発し、私たちはうまくいけば近いと近くにいくつかの最小。しかし、どこから始めるのかは重要ですか? よく考えてみましょう。 私たちが微積分のクラスに戻ってきたら、いくつかの問題は凸であり、彼らは巨大なボウルのような形をしています。 だから、ボウルのどこかで始めて、妥当なステップサイズを取る限り グラデーションに従うと、最終的にはボウルの底に向かいます。 しかし、多くの機械学習の問題は凸面ではありません。 ニューラルネットワークは悪名高く凸ではないが、これは、ボウルのような形になるのではなく、彼らは卵の木箱のような形をしています。 可能な限り多くの最小値がある場合、その中のいくつかは他のものより優れています。 だから初期化が重要です。 それについては後で詳しく説明します。 すぐに効率性について考えてみましょう。 損失関数の勾配を計算するとき、数学は勾配を計算するべきであることを示唆している 私たちのデータセットのすべての例にわたって。 これは、勾配のステップを保証する唯一の方法です正確に正しい方向にあります。 数百万または数十億の例を持つ大規模なデータセットの場合、 それは多くの計算をするだろう各ステップを実行する。 経験的に、人々は、全体を使用するのではなく単一の例による損失関数の勾配を計算する場合、データセット それは主にあまりにも動作します。彼らはもっと全体的な措置を講じる必要がありますが、良い解決に達するための総計算量はしばしばはるかに小さくなります。 これは、確率的勾配降下と呼ばれる。 実際には、中間的な解決法を採用しています。 1つの例またはデータセット全体を使用するのではなく、小さなバッチを使用しています。どこかに10〜1000個の例があります ステップを実行します。これはミニバッチ勾配降下と呼ばれます。 (出典:https://developers.google.com/machine-learning/crash-course/reducing-loss/an-iterative-approach)
3時間目の内容と重複していく気もしますが、更に詳しくみていきましょう!