GoogleAIの勉強:2時間目「フレーミング」
次は「フレーミング」です。こちらもビデオが用意されているので早速見てみましょう。
 |
| 出典:https://developers.google.com/machine-learning/crash-course/framing/ml-terminology |
動画の中身も日本語になるなんて、やっぱりGoogle翻訳すごいです。こちらの動画も1分40秒ほどとなっているので気合をいれて聞いていきます。 ここで扱われている例は迷惑メール。これを自動的に受信ホルダーに入れるか迷惑フォルダーに入れるかを判断するために、差出人やらヘッダー情報やらを参照するわけですが、まずは、どういうのが迷惑メールでどういうのが違うのかをデータから学習して予測していくことが機械学習の大枠ということみたいです。
MLの用語
械学習とは何ですか?MLシステムは、入力を結合して前に見たことのないデータに有用な予測を生成する方法
と、いうわけで機械学習を学習していく上で大切な用語があるようです。
ラベル
ラベルは「コレならコレ」という単純なもので、絵の中の動物の種類などが当てはまります。これをyとします
特徴
単純な機械学習プログラムであれば「コレならコレ」という単一ですが、高貴な(?)機械学習機能だと「コレとコレとコレがコウならコレ」のような数百万の機能を使用できます。 例えば、迷惑メールを判別するときも「本文・アドレス・送信時刻・迷惑メール特有のフレーズ」から「コレは迷惑メールだ!」と判断できるような感じです。
例
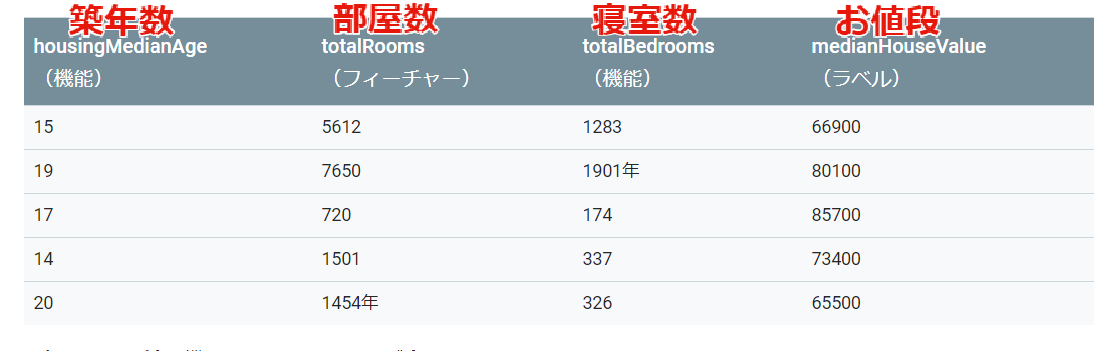
ここでカリフォルニアの住宅価格の表を元にした例が出てきます
 |
| 出典:https://developers.google.com/machine-learning/crash-course/framing/ml-terminology |
これを元に「ラベルされた例」と「ラベルされていない例」を見ていきます。 ラベルされた例として、 築年数15 部屋数5612 寝室数1283 の場合、価格(=ラベル)66900として認識されます。 ラベルされていないと導くデータのみしか使えないので、これを学習(トレーニング)していくと次のようなお値段(ラベル)がない場合にもお値段(ラベル)を予測してくれるようになると・・・
 |
| 出典:https://developers.google.com/machine-learning/crash-course/framing/ml-terminology |
モデル
モデルは、フィーチャ(部屋数)とラベルの関係を定義します。 たとえば、スパム検出モデルでは、特定の条件を「スパム」に”強く関連付ける”ことがあります。(例えば、有害サイトのURLが本文にあったらスパム判定など) トレーニングモデルを作成または学習することを意味します。モデルがフィーチャーとラベルの関係を徐々に学習できるようにします。 推論とは、訓練されたモデルをラベルのない例に適用することを意味します。つまり、訓練されたモデルを使用して有用な予測を作成。たとえば、築年数・部屋数・寝室数からお家のお値段を予測する感じです。
回期モデル・分類モデル
回帰モデルは連続値を予測します。たとえば、回帰モデルは、次のような質問に答える予測を行います。
- カリフォルニアの家の価格はいくらですか?
- ユーザーがこの広告をクリックする確率はどれくらいですか?
分類モデルは、離散値を予測します。たとえば、分類モデルは、次のような質問に答える予測を行います。
- 特定の電子メールメッセージが迷惑メールか迷惑メールですか?
- これは犬、猫、ハムスターのイメージですか?
ここまでが、サイト内のトレーニングの内容です。ところどころ追記とか書き換えをしているので、本当か?という箇所は本家をご確認ください。回帰モデルや分類モデルについては詳しく解説しているサイトもあるので、更に知りたい人は参照してみてください。
次のページには理解度テストがあります
理解度チェック
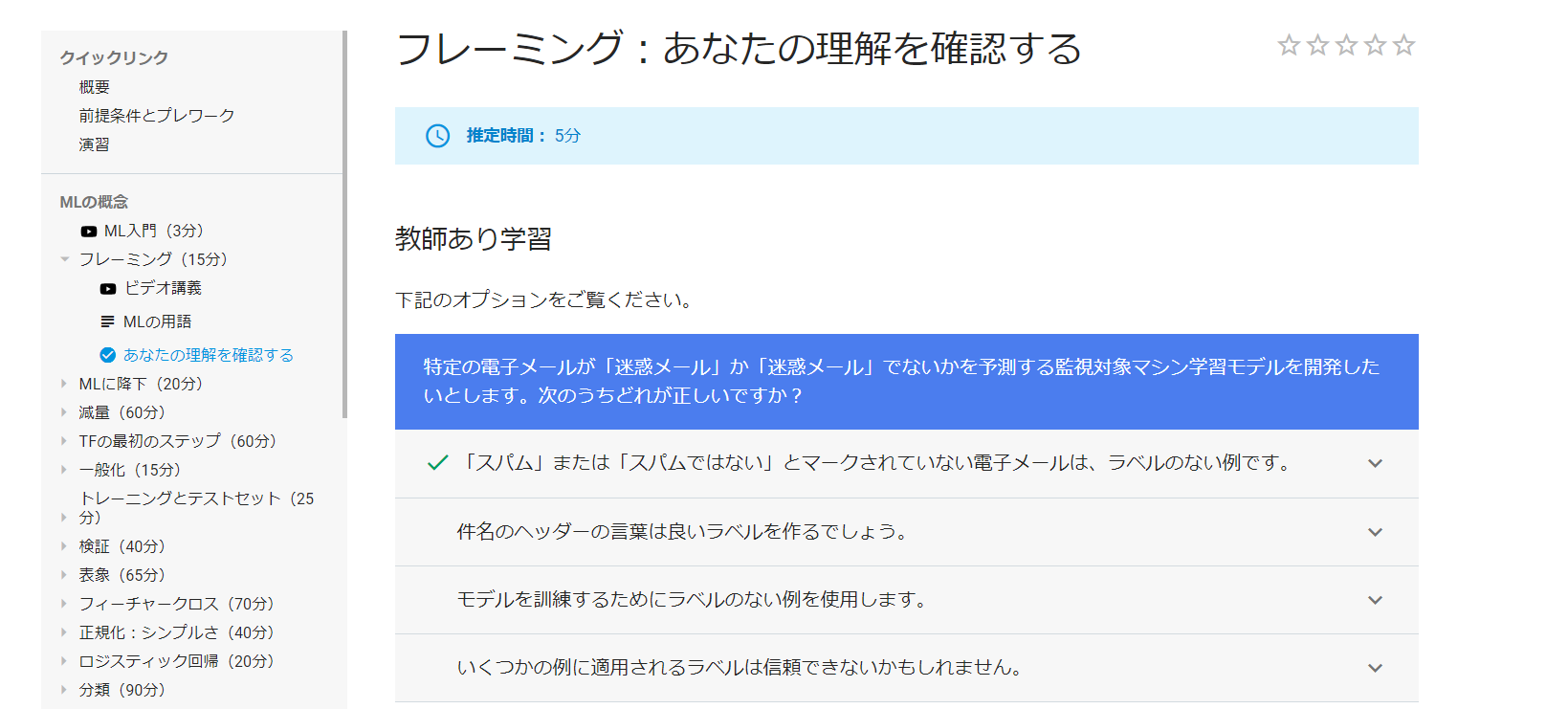
第一問:特定の電子メールが「迷惑メール」か「迷惑メール」でないかを予測する監視対象マシン学習モデルを開発したいとします。次のうちどれが正しいですか?
- 「スパム」または「スパムではない」とマークされていない電子メールは、ラベルのない例です。
- 件名のヘッダーの言葉情報はラベル判定にとても役立つでしょう。
- モデルを訓練するためにラベルのない例を使用します。
- いくつかの例に適用されるラベルは信頼できない。
答え:
- 【正解】私たちのラベルは "スパム"と "スパムではない"という値で構成されているため、まだスパムとマークされていない、またはスパムではない電子メールはラベルなしの例です。
- 【誤り】件名のヘッダーの言葉は優れた機能を発揮するかもしれませんが、良いラベルを作れません。
- 【誤り】ラベル付きの例を使ってモデルを訓練します。次に、ラベルなしの例に対して訓練されたモデルを実行して、ラベルなしの電子メールメッセージが迷惑メールか否かを推測することができます。
- 【正解】絶対にデータの信頼性を確認することが重要です。このデータセットのラベルは、おそらく、特定の電子メールメッセージをスパムとしてマークする電子メールユーザーのものです。ほとんどのユーザーは、疑わしい電子メールメッセージをすべてスパムとしてマークしないので、電子メールがスパムかどうかを知ることができない場合があります。さらに、スパムの発信者は、誤ったラベルを提供することによって意図的にモデルを害する可能性があります。
第二問:オンラインシューズストアが、ユーザーに適したシューズの推奨事項を提供するMLモデルを作成したいと仮定します。つまり、モデルはMartyにいくつかのペアのシューズを推奨し、Janetには異なるシューズペアを推奨します。次のうちどれが正しいですか?
- "靴の美しさ"は便利な機能です。
- 「ユーザーが嫌う靴」は有益なラベルです。
- 「靴のサイズ」は便利な機能です。
- 「ユーザーが靴の説明をクリックした」というのは有用なラベルです
答え:
- 【誤り】優れた機能は具体的で定量可能です。美しさはあまりにも漠然とした概念であり、有用な機能である。美しさは、おそらくスタイルや色などの特定の具体的な機能のブレンドです。スタイルや色はそれぞれ美しさよりも優れているでしょう。
- 【誤り】好き嫌いは、観測可能で定量可能な指標ではありません。私たちができることは、具体的に基準が決っているもののみです。
- 【正解】「靴のサイズ」は、ユーザーが推奨する靴を好むかどうかに強い影響を与える可能性のある定量化可能な情報です。たとえば、Martyがサイズ9を装着している場合、モデルはサイズ7のシューズを推奨しません。
- 【正解】ユーザーはおそらく、好きな靴についてさらに詳しく知りたいだけです。したがって、ユーザーによるクリックは、優れたトレーニングラベルとして役立つ、観測可能で定量化可能な測定基準です。
いかがでしたか?問題を解くとわかりにくい部分がスッキリしますね。